Từ cào dữ liệu đến trực quan hóa: Một quy trình xử lý dữ liệu toàn diện
Quy trình xử lý dữ liệu toàn diện: Từ cào dữ liệu, xử lý với PySpark, lưu trữ trên PostgreSQL, triển khai Docker, đến trực quan hóa bằng Power BI
Web | App | Data
Trong thời đại dữ liệu phát triển mạnh mẽ như hiện nay, việc thu thập, xử lý và lưu trữ dữ liệu từ nhiều nguồn khác nhau đã trở thành một yếu tố quan trọng giúp doanh nghiệp đưa ra các quyết định dựa trên dữ liệu (data-driven decisions). Bài viết này sẽ giới thiệu một quy trình đầy đủ và chi tiết về cách chúng tôi thực hiện cào dữ liệu từ các trang web, lưu trữ dữ liệu trên MongoDB, xử lý dữ liệu bằng PySpark, ghi dữ liệu đã xử lý vào PostgreSQL, triển khai Docker để dễ dàng quản lý môi trường, và cuối cùng trực quan hóa dữ liệu bằng Power BI. Cuối cùng, chúng ta sẽ cùng xem xét việc vẽ sơ đồ ERD (Entity Relationship Diagram) để trực quan hóa dữ liệu.
Bước 1: Cào dữ liệu
Cào dữ liệu (web scraping) là quá trình thu thập dữ liệu từ các trang web tự động thông qua việc lập trình. Dữ liệu cào được thường rất đa dạng, có thể là thông tin về sản phẩm, dịch vụ, hoặc thông tin khách hàng.
Trong dự án của tôi, dữ liệu cào được lấy từ các nguồn trực tuyến, bao gồm thông tin về doanh thu bán hàng, số lượng đơn hàng, và chi tiết khách hàng. Mục tiêu của bước này là thu thập càng nhiều dữ liệu thô có giá trị nhất từ web để phục vụ cho quá trình xử lý sau này. Tuy nhiên, điều quan trọng cần lưu ý là việc cào dữ liệu cần tuân thủ đúng các chính sách pháp lý của trang web.
Bước 2: Đổ dữ liệu lên MongoDB
Sau khi thu thập được dữ liệu từ bước cào, chúng tôi lưu trữ dữ liệu này vào MongoDB – một cơ sở dữ liệu NoSQL có khả năng lưu trữ dữ liệu linh hoạt và hiệu quả. MongoDB rất phù hợp để lưu trữ các loại dữ liệu phi cấu trúc hoặc dữ liệu có cấu trúc phức tạp như dữ liệu thô từ web. Các bản ghi được tổ chức dưới dạng các document trong collection, điều này giúp chúng tôi có thể dễ dàng truy vấn và xử lý dữ liệu sau này.
MongoDB cung cấp khả năng lưu trữ dữ liệu mạnh mẽ và dễ dàng mở rộng, đặc biệt là trong các ứng dụng xử lý dữ liệu lớn.
Bước 3: Xử lý dữ liệu bằng PySpark
Dữ liệu cào về từ web thường rất "bẩn" và có nhiều lỗi, do đó chúng tôi cần xử lý trước khi phân tích sâu hơn. Đây là lúc PySpark (một công cụ xử lý dữ liệu lớn) phát huy tác dụng.
Chúng tôi sử dụng PySpark để tải dữ liệu từ MongoDB, tiến hành xử lý dữ liệu như loại bỏ dữ liệu trùng lặp, chuẩn hóa thông tin và làm sạch các trường dữ liệu không cần thiết. PySpark giúp tối ưu hóa quá trình xử lý dữ liệu lớn nhờ khả năng tính toán phân tán trên nhiều máy chủ, giúp việc xử lý dữ liệu diễn ra nhanh chóng và hiệu quả.
Một số phép toán quan trọng mà chúng tôi thực hiện trong bước này bao gồm:
Tính tổng doanh thu từ các đơn hàng
Phân tích số lượng đơn hàng theo sản phẩm
Theo dõi và phân loại khách hàng dựa trên các chỉ số mua hàng
Bước 4: Lưu trữ dữ liệu đã xử lý vào PostgreSQL
Sau khi dữ liệu đã được xử lý và làm sạch, bước tiếp theo là lưu trữ dữ liệu vào PostgreSQL – một cơ sở dữ liệu quan hệ. PostgreSQL cung cấp khả năng lưu trữ dữ liệu với độ chính xác và toàn vẹn cao, phù hợp để lưu trữ dữ liệu đã qua xử lý, đặc biệt là khi chúng tôi cần làm việc với các truy vấn SQL phức tạp sau này.
Việc lưu trữ dữ liệu vào PostgreSQL giúp chúng tôi dễ dàng thực hiện các phân tích chuyên sâu hơn trong tương lai, đồng thời hỗ trợ cho việc báo cáo và trực quan hóa dữ liệu. Hơn nữa, PostgreSQL hỗ trợ các ràng buộc quan hệ giữa các bảng dữ liệu, giúp đảm bảo tính chính xác và nhất quán của thông tin.
Bước 5: Build toàn bộ lên Docker
Để đảm bảo môi trường chạy ứng dụng ổn định và dễ dàng triển khai trên nhiều máy chủ khác nhau, chúng tôi đã quyết định build toàn bộ hệ thống lên Docker. Docker giúp đóng gói ứng dụng và các phụ thuộc của nó vào các container, đảm bảo rằng ứng dụng của chúng tôi chạy đồng nhất trên mọi môi trường mà không lo vấn đề về cấu hình hệ thống.
Trong dự án này, chúng tôi xây dựng từng thành phần bao gồm:
Container cho MongoDB: Để lưu trữ dữ liệu chưa qua xử lý
Container cho PySpark: Để xử lý dữ liệu lớn
Container cho PostgreSQL: Để lưu trữ dữ liệu đã qua xử lý
Container cho ứng dụng web: Để giao tiếp với cơ sở dữ liệu và hiển thị kết quả phân tích
Mỗi container hoạt động độc lập và được quản lý thông qua Docker Compose để dễ dàng khởi động và tắt đi cùng một lúc. Docker cung cấp sự tiện lợi không chỉ cho việc phát triển mà còn trong quá trình triển khai thực tế.
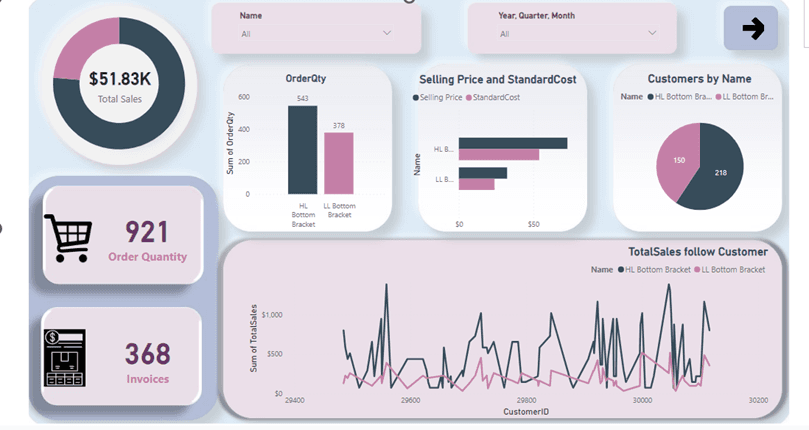
Bước 6: Trực quan hóa dữ liệu bằng Power BI
Sau khi lưu trữ dữ liệu vào PostgreSQL, để giúp các bên liên quan có thể dễ dàng nắm bắt thông tin và ra quyết định, chúng tôi sử dụng Power BI để trực quan hóa dữ liệu. Power BI cho phép chúng tôi tạo các biểu đồ tương tác, các báo cáo sinh động và dễ hiểu.
Một số biểu đồ mà chúng tôi tạo bao gồm:
Tổng doanh thu: Dùng biểu đồ hình tròn để thể hiện doanh thu tổng theo các sản phẩm hoặc danh mục
Số lượng đơn hàng: Dùng biểu đồ cột để thể hiện sự thay đổi số lượng đơn hàng qua các tháng/quý
Theo dõi khách hàng: Dùng biểu đồ đường để theo dõi xu hướng mua sắm của khách hàng trong khoảng thời gian nhất định
Power BI giúp chúng tôi không chỉ dễ dàng theo dõi các chỉ số kinh doanh mà còn cung cấp khả năng tương tác với dữ liệu theo nhiều chiều khác nhau.
Bước 7: Vẽ sơ đồ ERD (Entity Relationship Diagram)
Cuối cùng, để trực quan hóa cấu trúc dữ liệu và các mối quan hệ giữa các bảng trong cơ sở dữ liệu, chúng tôi đã vẽ sơ đồ ERD (Entity Relationship Diagram). Sơ đồ ERD giúp mô tả rõ ràng các thực thể (entity) như Customer (khách hàng), Order (đơn hàng), Product (sản phẩm) và các mối quan hệ giữa chúng.
ERD đóng vai trò quan trọng trong việc thiết kế cơ sở dữ liệu và giúp chúng tôi hiểu rõ hơn về cách dữ liệu được tổ chức, từ đó dễ dàng hơn trong việc truy vấn và phân tích.
Kết luận
Quy trình xử lý dữ liệu từ việc cào dữ liệu, đổ vào MongoDB, xử lý bằng PySpark, lưu trữ trong PostgreSQL, và trực quan hóa bằng Power BI là một quy trình toàn diện giúp đảm bảo rằng dữ liệu thô thu thập được từ web có thể được xử lý và tối ưu hóa cho các nhu cầu phân tích và kinh doanh. Sự kết hợp của Docker giúp việc triển khai trở nên dễ dàng hơn, trong khi Power BI cung cấp cái nhìn sâu sắc về dữ liệu thông qua các biểu đồ trực quan. Với sự hỗ trợ của các công cụ mạnh mẽ này, chúng tôi có thể dễ dàng quản lý dữ liệu lớn và đưa ra các báo cáo chi tiết phục vụ cho việc ra quyết định dựa trên dữ liệu.
Tác giả: Cao Võ Thanh Tòng

